
How to Collect 100+ Related Questions to Your Target Keywords

Leonardo
November 11, 2023
Discover Proven Strategies to Boost Your Content Marketing Efforts and Enhance Search Visibility. Master the Art of Question Mining for SEO Success!
 As search engine visibility gets more and more important – especially with social media engagement and tracking going down –, SEO has increasingly become a high-competitive channel.
As search engine visibility gets more and more important – especially with social media engagement and tracking going down –, SEO has increasingly become a high-competitive channel.So how can your website carve a place in the vast results the web provides? Well, the answers might lie in the questions!
In today’s article, we’re going to build a “People Also Ask” scraper to collect hundreds (or even thousands) of related questions around your target keywords, allowing you to build a more comprehensive topic cluster, optimize your content, and improve search intent.
What’s “People Also Ask”?
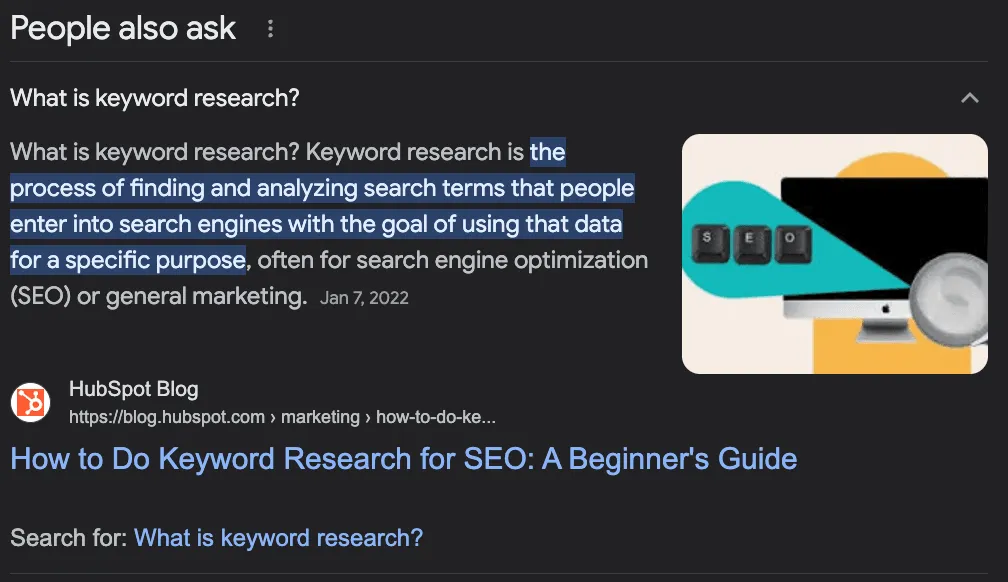
Google's "People Also Ask" feature is a section of search results that shows related questions and answers from other sources. It helps users find more information about their query or explore different aspects of the topic.
The feature is dynamic and can expand or change depending on the user's interaction.
How to Use PAA Questions to Boost Your SEO
Although “People Also Ask” (PAA) is mainly an end-user feature, it can be a great ally in creating and optimizing your site’s content.
The idea behind PAA is to help users find additional information about their query or help lost users who aren’t sure how to search for a piece of information, so Google needs to “predict” the intent behind the search.
Get the idea now?
PAA questions are a great way to identify potential questions your content should be answering – increasing topic authority – or new topics to create content around your main keyword.
For example, let’s say you want to write a piece about doing keyword research. What should you cover?
Most people will search for the target term in Google, take a look at what’s already ranking, and call it a day.
However, if we check the PAA box, we’ll find some interesting ideas:
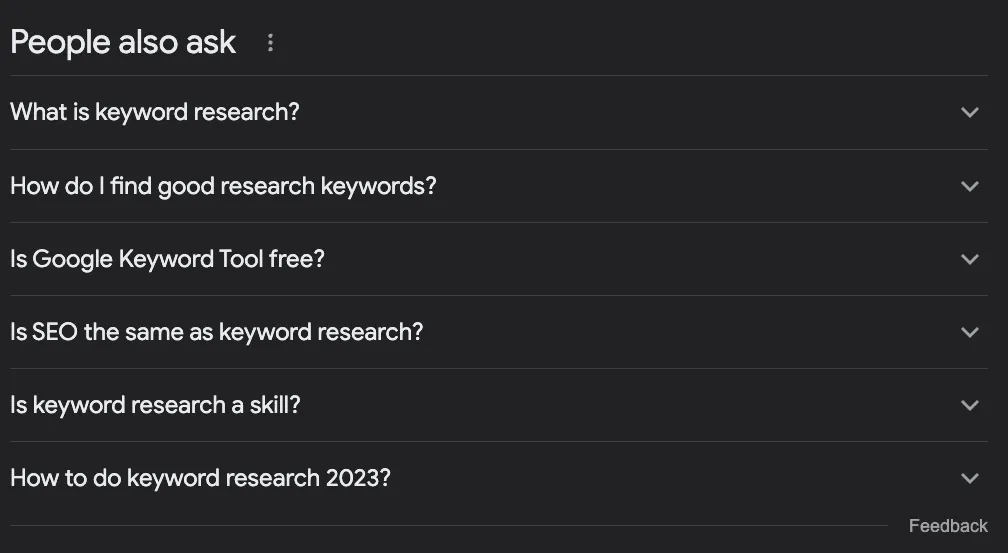
What is keyword research?
How do I find good research keywords?
Is Google Keyword Tool free?
Is SEO the same as keyword research?
How to do keyword research 2023?
From these questions alone, we can determine a few things:
The question “Is SEO the same as keyword research?” tells us that this is a very entry-level topic, so people searching this term are beginners, and we should set the tone for them.
It is an evolving topic that needs to be updated frequently as we have a question about the current year.
We should add a section with the headings “What is Keyword Research?” and “How Do I Find Good Search Keywords” – I wouldn’t use the second one exactly like that, but you get the point.
We should mention how to use “Google Keyword Planner” as part of the tutorial, as Google ties it to the query.
We can get a lot of valuable information about our keywords, build a list of related keywords, optimize our content to answer common questions around the target keyword, and find new topic ideas to build complete topic clusters.
Collecting “People Also Ask” Questions with Python
There’s a challenge, though. Collecting all these questions for our existing content or to use as support for planning our content is a time-consuming and resource-intensive task.
SEOs and content managers already have a lot of work to add extra research, so how do we solve that?
Simple, we automate the process!
We’ll build a web scraper that:
Take a list of keywords
Navigate to the keyword’s SERP
Extract all PAA questions
Export the information into a CSV
For this tutorial, we’ll use Python with a simple tool to take care of all the complexity, and you’ll be able to use the resulting code by just changing the keywords.
Ready? Let’s get started.
Step 1: Setting Up Your Project
The first thing to do is create a new folder for your project (name it paa-scraper) and create a new paa_scraper.py file inside.
If you’re on Mac, your machine already has a version of Python installed. If you’re on Windows, follow this tutorial to get it on your machine.
Next, open the folder in VScode and a new terminal.
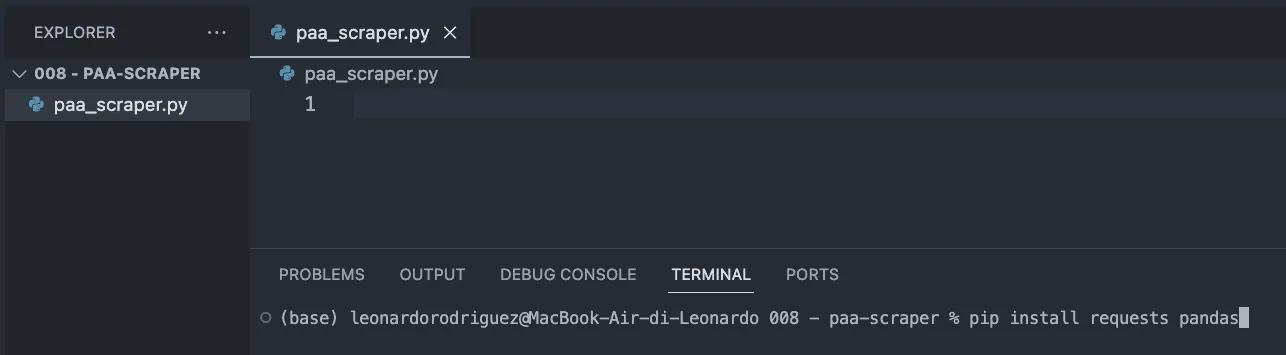
From there, enter the following command.
pip install requests pandas
The command above will install two useful tools (dependencies):
Requests will let us ask for the information we want to extract
Pandas will help us export the information as a CSV file
To finish this step, import both dependencies at the top of the file.
import requests
import pandas as pd
Step 2: Sending Our Request Through ScraperAPI
Traditionally, to get the data we’re looking for, we would have to build a scraper that navigates to Google, search for the information using CSS selectors, pick the information, format it… you know what I mean? It’s usually a lot of logic.
Instead, we can use a web scraping tool to reduce costs, implementation time, and maintenance.
By sending our request through ScraperAPI�’s structured data endpoints, we’ll be able to retrieve the PAA questions of any query without worrying about parsing the HTML, getting blocked, or any other issue we might face.
To get started, create a free ScraperAPI account and go to your dashboard to copy your API key.
Then, we’ll create a payload like this:
payload = {
'apikey': 'YOURAPI_KEY',
'country': 'us',
'query': 'keyword+research',
}
The country parameter will tell ScraperAPI from where to send your requests – remember Google shows different results based on your location – while the query parameter holds your keyword.
With these parameters ready, we can send our request using the get() method:
response = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
Step 3: Printing PAA Questions
If we print(response.text), this is the information we get:
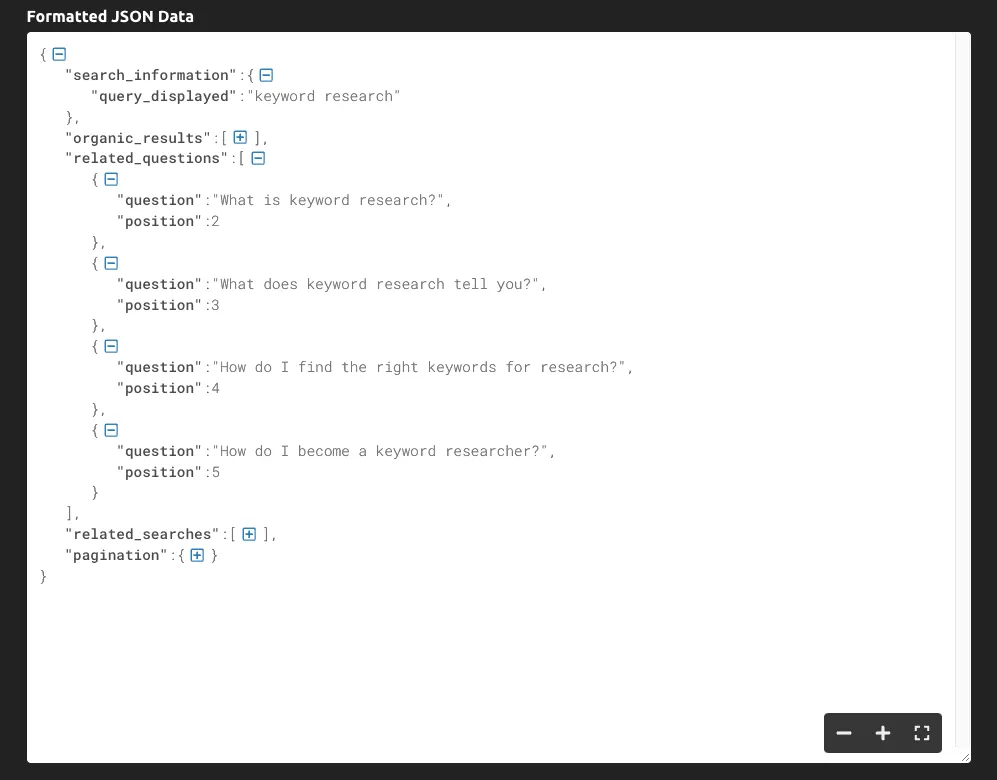
As you can see, the tool returns the entire SERP as JSON data, and the main questions related to the query are inside the “related_questions” key.
Because we’re getting structured data instead of raw HTML data, we can select specific elements using their key name:
serp = response.json()
allquestions = serp['relatedquestions']
for paa in all_questions:
print(paa['question'])
We store the entire JSON response into a serp variable
We grab the “related_questions” and create a list of items – where each item is a PAA question
To grab the questions, we loop through the list and print only the “question” key
The result of this is a list of PAA questions printed on the console:

Step 4: Exporting the Data to a CSV File
For the CSV file, we might also want to match the keyword with the PAA question, so let’s grab it:
keyword = serp['search_information']['query_displayed']
After this is done, we’ll create an empty list we’ll use to format the data as we want:
paa_questions = []
And append the extracted information to it:
for paa in all_questions:
paa_questions.append({
'Keyword': keyword,
'Related Question': paa['question']
})
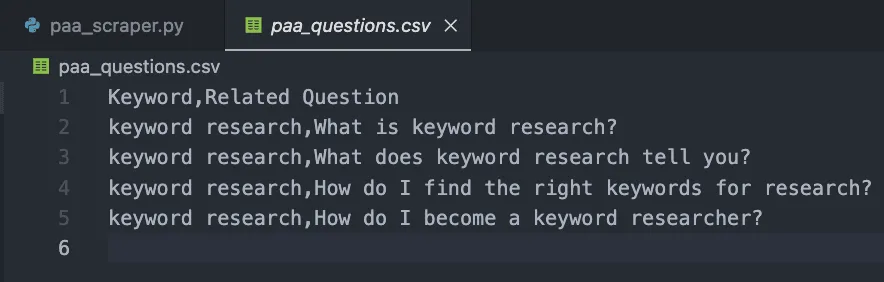
If we print paa_questions, here’s how it looks in the console:

This is important because it is the base of the CSV file and will help us identify where’s the question coming from when we expand the scraper to thousands of keywords.
For the last step, let’s create the CSV file using Pandas for easy export:
db = pd.DataFrame(paa_questions)
db.tocsv('paaquestions.csv', index=False)
If you run your code now, it won’t print anything to the console. Instead, it’ll create a new CSV file like this:
Step 5: Collecting PAA Questions at Scale
Of course, getting the questions for just one keyword can be done by hand, so how do we scale this project?
Well, here’s the beauty of web scraping. It’s all about the loop!
First, create a list with your desired keywords:
keywords = {
'keyword+research',
'keyword+tracker'
}
Then, we’ll put all our previous code inside a new loop, which will take each term within the keywords list and run the entire process.
Here’s the final and full code snippet:
import requests
import pandas as pd
paa_questions = []
keywords = {
'keyword+research',
'keyword+tracker'
}
for query in keywords:
payload = {
'apikey': 'YOURAPI_KEY',
'country': 'us',
'query': query,
}
response = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
serp = response.json()
keyword = serp['search_information']['query_displayed']
allquestions = serp['relatedquestions']
for paa in all_questions:
paa_questions.append({
'Keyword': keyword,
'Related Question': paa['question']
})
db = pd.DataFrame(paa_questions)
db.tocsv('paaquestions.csv', index=False)
For testing purposes, we only added two, but you can create a list of thousands or even millions of targeted keywords.
The result is an easy-to-read CSV file:
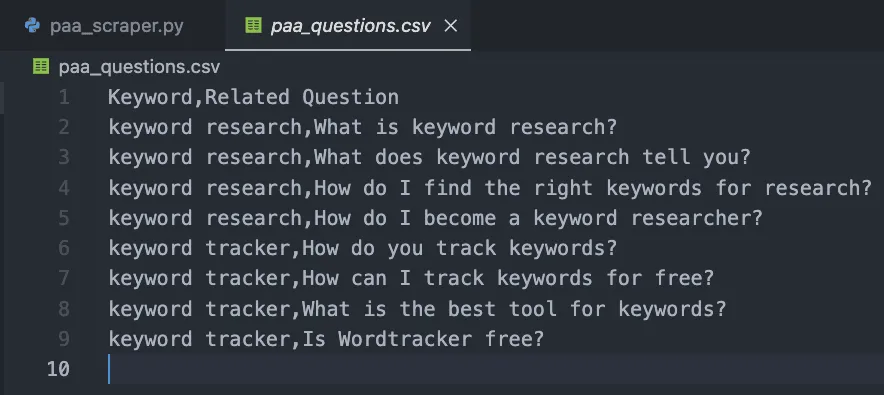
Congratulations, you just collected your first 9 PAA questions! 🎉
Wrapping Up
In this article, you’ve learned how to:
Start a new Python scraper
Send HTTP requests through ScraperAPI
Pick specific data points
Format the extracted data
Export the data to a CSV file
You can make the code above your own by adding your API key and list of keywords inside the keywords variable. You can also use the same logic to collect top rankings for every target keyword, scaling your research efforts by automating these processes.
If you don’t want to handle coding, you can also use ScraperAPI’s DataPipeline, a no-code tool designed to automate entire scraping projects without writing a single line of code. Just add your list of keywords and let the tool do the rest.
Collecting and using PAA questions to improve your site’s content is a secret weapon most SEO professionals ignore. Data is your best friend if you know how to use it, so get creative and push the limits to dominate your niche!
Related blog posts
Why You Need Both LLM and Rank Tracking
Learn why SEOs need both rank tracking and LLM tracking to measure and understand their visibility across SERPs and AI answers.
12 March 2026
From Setup to First LLM Insights in No Time
If you have not started tracking prompts yet, this is where to begin. We show you how to go from zero setup to first LLM insights in no time.
26 February 2026
How to Choose the Right AI Visibility Tool
Learn how to choose the right LLM tracking tool to monitor AI visibility. We go through key features, integrations, capabilities, and budget.
3 February 2026